Definitions, Formulae
Nikolai Shokhirev
Definitions
| n-th moment | 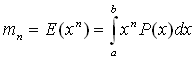 |
(1) |
| Norm | |
(2) |
| Mean | |
(3) |
| n-th central moment | |
(4) |
| Variance | |
(5) |
| Std deviation | |
(6) |
| Skewness | μ3 / σ3 | (7) |
| Kurtosis | μ4 / σ4 | (8) |
| Excess kurtosis | μ4 / σ4 - 3 | (9) |
Useful relations
| μ2 = m2 - m12 | (10) |
| μ3 = m3 - 3 m2 m1+ 2 m13 | (11) |
| μ4 = m4 - 4 m3 m1+ 6 m2 m12 - 3 m14 | (12) |
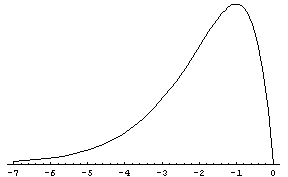
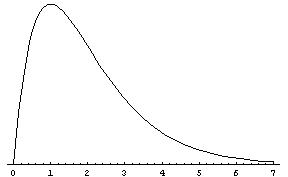
Skewness example
Power-exponential function:
 |
 |
|
Negative skew, left-skewed. |
Positive skew, right-skewed. |
See more examples in Distributions.
Kurtosis terminology
A high kurtosis distribution has a sharper "peak" and flatter "tails", while a low kurtosis distribution has a more rounded peak with wider "shoulders".
- Distributions with zero excess kurtosis are called mesokurtic, or mesokurtotic. The most prominent example is the normal distribution.
- A distribution with positive excess kurtosis is called leptokurtic, or leptokurtotic. Laplace distribution (double exponential distribution), excess kurtosis = 3.
- A distribution with negative excess kurtosis is called platykurtic, or platykurtotic. Uniform distribution, excess kurtosis = -1.2.

Laplace distribution.
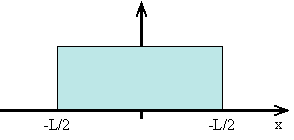
Uniform distribution.
See more examples in Distributions.
Sample estimators
In practice, often the density functions P(x) are not available and only a limited number of a random variable is available: xi , i = 1, . . . , N . So-called sample estimators can be used instead of (1):
| n-th moment | 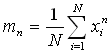 |
(13) |
Note, that mn as the sum of random variable is a random variable itself. It has its expectation (mean) value and standard deviation. An estimator is called "unbiased" if its expectation value is equal to the exact (population) value. For example, E(m1) = μ, is an unbiased estimator; E(m2 - m12) = σ2 N/(N - 1), is biased (although it tends to σ2 as N → ∞).
Unbiased estimators
| Mean | m1 | (14) |
| Variance | 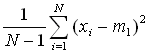 |
(15) |
| Skewness | 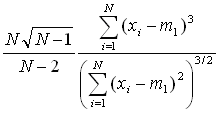 |
(16) |
| Excess kurtosis | 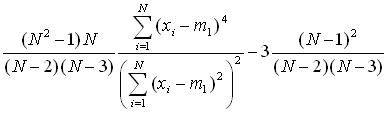 |
(17) |
References
- http://en.wikipedia.org/wiki/Moment_%28mathematics%29
- http://en.wikipedia.org/wiki/Variance
- http://en.wikipedia.org/wiki/Bias_of_an_estimator
- http://en.wikipedia.org/wiki/Skewness
- http://en.wikipedia.org/wiki/Kurtosis